Biography
I’m a graduate student pursuing MASc in AI (research) at Queen’s University. My research interests include Generative models, Self-supervised learning, Multi-modality, and learning universal representations of time-series. I’m an author of 10+ publications, encompassing a total of 100+ citations. Apart from research, I have prior experience in Data engineering and deploying Machine learning models at scale on cloud/serverless to integrate with real-world products/applications.
Achievements:
- Vector Scholarship in AI
- MITACS Globalink Graduate Fellow
-
MASc in Artificial Intelligence, September 2022 to Present
Queen's University
-
B.Tech in Electronics and Telecommunication, July 2018 to July 2022
KIIT University
Experience
Overview:
- Graduate research supervised by Dr. Ali Etemad.
- Implemented a state-of-the-art High-Fidelity PPG-to-ECG translation system powered by a novel class of Diffusion Models. Demonstrated the ability to detect a range of Cardiac conditions/diseases using synthetic ECGs with significantly higher F1 than the input PPGs. Paper under review at an A* conference.
- Developed a Speech Emotion classifier capable of explicitly understanding the linguistic and prosodic aspect of emotions using Cross-modal Knowledge distillation. Experiments show state-of-the-art performance on IEMOCAP. Paper to be submitted at an A* conference.
Overview:
- Presently working on few-shot prompt learning on spoken content, for SHL’s Interview Intelligence platform.
- Developed algorithms for repititive phrase, filler phrase, self introduction and organization introduction detection.
Overview:
- Collaborated with a PhD student for a project focused on modeling continuous conformational changes in cryo-ET images with Unsupervised representation learning under the supervision of Dr. Min Xu.
- Conducted a comprehensive literature review and baseline method implementations.
Overview:
- Conducted cross-disciplinary research at the intersection of Deep learning and wireless communications, under the supervision of Dr. Omer Waqar from Thompson River’s University, Canada.
- Authored a comprehensive review paper addressing a gap in literature on the bi-directional interplay of Federated learning and wireless communications, accepted at the journal - Transactions on Emerging Telecommunications Technologies.
- Designed a novel unsupervised learning algorithm for energy and power optimization in UAV networks. The paper was presented at IEEE UEMCON 2021, and recieved the Best Presenter award.
Overview:
- Leading the project on variable-length synthetic handwriting image generation using Generative Adversarial networks.
- Academia-Industry colloraboration with a 6-member team consisting of myself, another student, Prof. Vimal Srivastava, Prof. Manoranjan Kumar and two mentors from Samsung Research, Bangalore.
- Generated synthetic data is being utilized to train better handwritten text recognition (HTR) models for HTR feature in Samsung smartphone’s OCR system.
Overview:
- Focused on building full stack data science pipeline from data collection to model deployment for powering the AI engine of Relevense (https://www.relevense.com/), a Flagship market intelligence product co-funded with grants of the Europees Fonds voor Regionale Ontwikkeling (EFRO) and Samenwerkingsverband Noord Nederland (SNN).
- Projects include Tweet based emotion recognition API, Big-5 personality classication API, Facial expression recognition, Receptive audience recommendation system.
- Reduced the AWS costs by 60% by shifting the backend to a serverless architecture with multiple Lambda functions, DynamoDB, Timestream and S3.
- Single handedly created end-to-end ML pipelines with all models beyond 95% accuracy along with efficient monitoring of out of training distribution inference events.
Overview:
- Collaborated with a team of 48 while working with our client, World Resources Institute (https://www.wri.org/) on a project leveraging NLP to find geographical locations with climate hazards and potential gaps for minimizing climate change impacts across the globe. Deployed a dashboard designed with Streamlit for easy inference. Technical blog on the project: https://omdena.com/blog/climate-change-impacts/ .
- Led a team of 48 for building the data processing and machine learning backend for a Dutch client’s market intelligence product. Got a full-time offer from the client due to extraordinary contributions in the project.
Overview:
- Built an end-to-end NLP pipeline for Multi-document abstractive summarization of Radiology reports of COVID-19 patients
- Trained longformer and BERT models on a Slurm multi-GPU cluster in an HIPAA protected server.
- Achieved a ROUGE-1 score of 0.410 on test dataset.
Overview:
- Developed a full stack web-based invoice management application following an end-to-end Data science product development lifecycle guided by mentors.
- Responsibilities included identifying appropriate user requirements, designing a great user experience and building appropriate data pipelines and machine learning models along with relevant UI components and backend design.
- Developed a state-of-the-art payment prediction system using XGboost regression, with a root-mean-squared error of 0.1 on 5-fold cross validation.
Recent Publications
Featured Publications
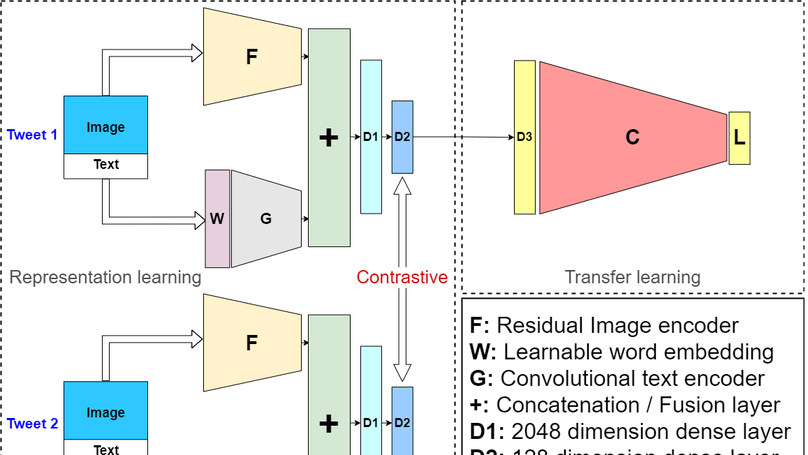
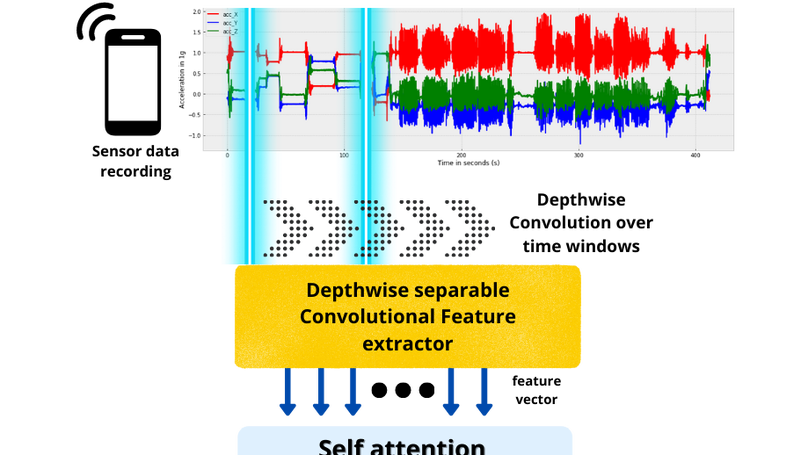
In recent times, surge in the use of smartphones in our daily lives has created a huge opportunity for paving the road towards human-centric computing by utilizing the rich data which gets recorded by it’s multiple sensors. Sensor-based human activity recognition has a tremendous amount of real-world applications such as health monitoring, surveillance, smart homes, and ambient assisted living. This paper presents a joint residual feature extractor and a transformer-based deep neural network for end-to-end human activity recognition using raw multi-sensor data captured from smartphones or wearable devices. Unlike conventional handcrafted feature extraction, this approach outperforms all present approaches showing state-of-the-art generalizable performance over multiple benchmark datasets. It achieves a test accuracy of 95.2% on the UCI HAR dataset and 96.4% test accuracy on the WISDM dataset.
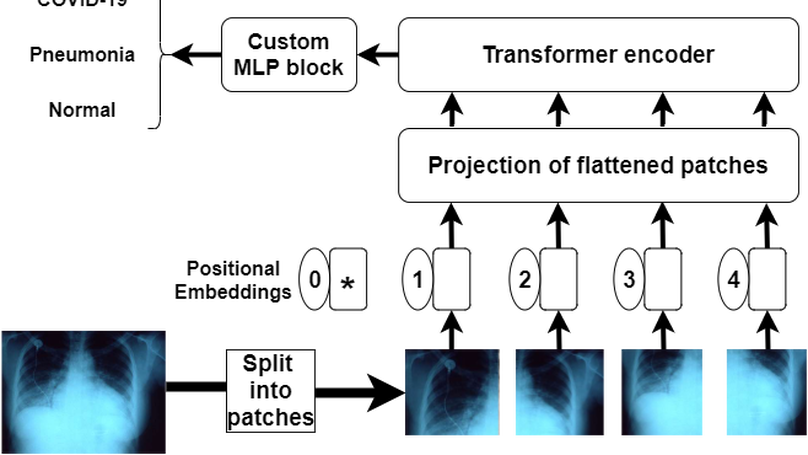
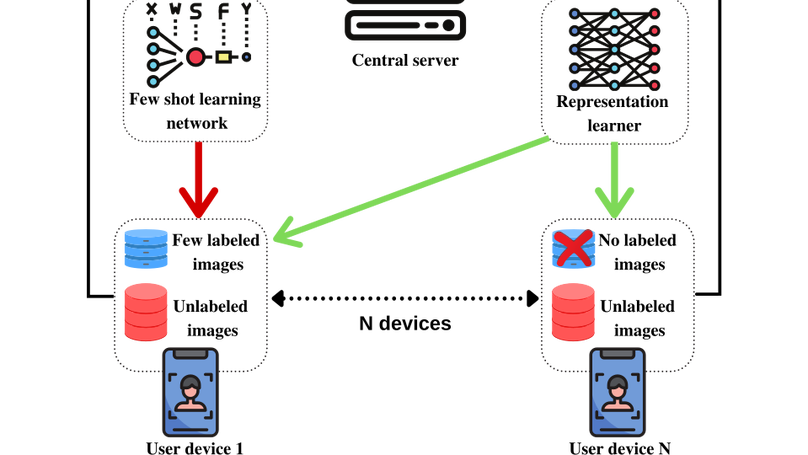
Certifications
Projects
Coming soon, website under construction !
Recent & Upcoming Talks
Coming soon, website under construction !
Recent Posts
Coming soon, blog under construction!
Contact
- debadityashome9@gmail.com
- 918927630639
- Park Plaza, Kharagpur, West Bengal 721301
- Enter Building and take the stairs to Floor 2